在昨天天的內容裡,我們已經介紹了 Dense Retrieval 與 Sparse Retrieval,以及並透過 Hybrid Search 把兩者結合在一起,目的是讓檢索結果更加精準。
其中,我們使用Hybrid Search 後還採用了RRF (Reciprocal Rank Fusion),來重新排序,這其實是一種Rerank(重排序) ,今天我們就來深入討論這個關鍵的RAG技術。
先快速帶給大家基本概念,後面再深入討論技術實踐:
初步檢索只是「粗篩」:
向量檢索或 BM25 檢索的主要目標是從大量的文件或段落中「快速找到相關候選文件」,重點是效率。
語意理解進行排序:
Rerank 模型背後技術是進行「查詢與文件的語意關係」比較,使用更複雜的演算法達到目的,重點是相關性的精確度。
效能與精度的折衷:
檢索階段負責快速找到關聯,Rerank 階段則負責產出更精確的相關度。
所以我們可以理解到Retrieval的任務就是在處理相關性,而Bi-Encoder和Cross-Encoder這兩項技術,就是自然語言處理(NLP)裡面最主要用來處理相似度、排序這類型問題的演算法。
我們這邊就來深入了解一下Bi-Encoder和Cross-Encoder
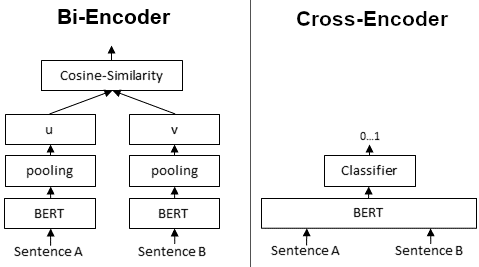
圖片來源:
sentence transformer
| 特性 | Bi-Encoder | Cross-Encoder |
|---|---|---|
| 運算方式 | 查詢與文件分別編碼,再比對相似度 | 查詢與文件拼接,一起輸入模型 |
| 效率 | 高,可處理百萬級文件 | 低,每組 pair 都要跑一次模型 |
| 精度 | 中等 | 高(能捕捉細粒度語義) |
| 適用場景 | 初步檢索、大規模匹配 | Rerank、需要高精度的小規模排序 |
| 典型流程 | 向量化 + ANN 搜索 | 精排前 10~100 文件 |
在實務應用中,常見做法是:
👉 先對大量資料做搜尋提高 效率,再針對第一輪過濾後的資料作篩選來確保了 答案品質。
如同先前提到embedding model必須要留意是否有支援中文,Reranker 模型一樣也是要選擇是能支援中文的,否則反而會越排越差。目前常見的 Reranker 多來自英文或簡體中文語料,如果只有支援純英文的就不要選擇了,整理幾項應注意的點:
多語言模型
中文專用模型
BAAI/bge-reranker-large) 已在中文語料上訓練,對繁體中文的支援性通常比純英文模型好。繁體中文微調
👉 建議策略:
bge-reranker-large 作為 baseline。在下一篇文章中,我們會更深入探討如何評估檢索與排序的效果。這裡先給出幾個常見指標:
👉 明天我們將從這些指標開始,進一步討論如何衡量 檢索 + Rerank pipeline 的整體表現。

